El Laboratorio de Semántica Computacional (LABSEMCO) realiza investigación básica y aplicada en Inteligencia Artificial, particularmente en el campo del Procesamiento Estadístico del Lenguaje y el desarrollo de Interfaces Cerebro Computadora. Somos un equipo multidisciplinario de investigadores profesionales y en formación, en áreas afines a la Inteligencia Artificial.
Es así que integramos estudiantes y colaboradores cuyas disciplinas abarcan: Matemáticas (puras y aplicadas), Física (sistemas complejos y dinámicos), Psiquiatría y Psicología, Lingüística cognitiva y computacional, y Ciencias de la computación (teórica y aplicada).
Colaboradores
Dr. Gerardo Mauricio Toledo Acosta (Matemáticas puras y aplicadas). Investigador postdoctoral en el Labsemco.
Dr. Markus Mueller (Análisis de sistemas complejos). Investigador del departamento de Física del CInC.
Dra. Asela Reig Alamillo (Lingüística cognitiva). Investigadora del Centro de Investigación en Ciencias Cognitivas (CINCCO).
estudiantes
Eliseo Morales González. Licenciatura en Ciencias (IICBA-UAEM).
David Torres Moreno. Maestría en Ciencias Cognitivas (CINCCO-UAEM).
Bolívar Martínez Zaldívar. Licenciatura en Matemáticas (FC-UNAM).
Mark Joseph Hernández Estrada. Maestría en Optimización y Cómputo Aplicado (FCAeI-UAEM)
Líneas de Investigación
Buscamos desarrollar sistemas artificiales capaces de adquirir y utilizar conocimiento de carácter semántico, con el fin de extender las capacidades humanas de extracción de información y facilitar la interacción Hombre-Máquina, mediante la comprensión de lenguaje natural y otras formas no-verbales de comunicación.
Modelación semántica
La sintaxis se refiere a la gramática, mientras que la semántica se refiere al significado. La sintaxis es el conjunto de reglas necesarias para garantizar que una frase sea gramaticalmente correcta; la semántica es el modo en que el léxico, la estructura gramatical, y otros elementos de una frase se unen para comunicar su significado.
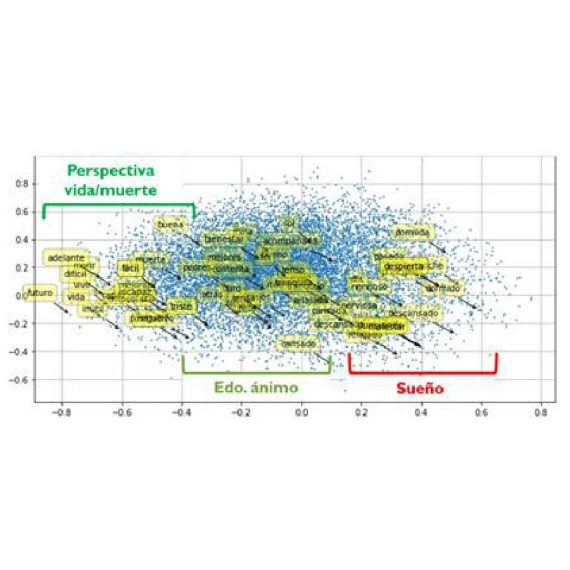
En una acepción de representación semántica, un modelo semántico de texto busca representar las relaciones que existen entre valores específicos de los rasgos que caracterizan los aspectos semánticos de un texto. Por ejemplo, en una oración, estos rasgos consisten en los elementos léxicos o de texto que responden a las preguntas de ¿quién?, ¿qué?, ¿cómo?, o ¿cuándo? Es así que un modelo semántico consiste por lo general en una estructura de datos inherentemente especificada por el conjunto de rasgos lingüísticos o de relaciones semánticas entre las unidades de texto (e.g. un grafo). En otra acepción de representación semántica, una palabra, por lo general, no transmite ningún significado sino hasta que figura en un contexto.
En este sentido, el significado de una palabra está dado por el contexto en donde ocurre. Esta es la acepción de la semántica distributiva, donde los modelos de aprendizaje profundo recientes, como los transformadores, han logrado avances significativos en tareas de Procesamiento de Lenguaje Natural (PLN). Nuestro trabajo aquí consiste en investigar modelos de aglomeración y representación con el fin de encontrar relaciones semánticas entre unidades de texto de complejidad variable: desde palabras hasta relaciones discursivas.
Aprendizaje de Representaciones
El aprendizaje de representaciones consiste en hacer que una máquina aprenda patrones abstractos que den sentido a los datos. Un modelo de aprendizaje automático no puede ver, oír o percibir directamente los ejemplos de entrada. En su lugar, debe crear una representación de los datos para proporcionar al modelo un punto de vista útil sobre las cualidades clave de los datos.
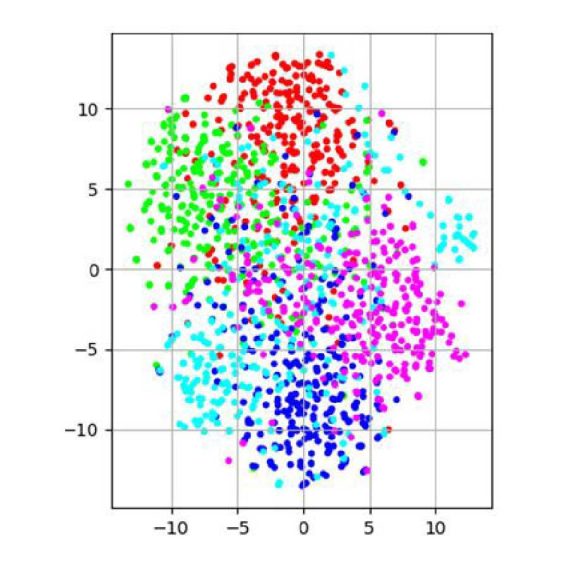
El aprendizaje profundo permite que los modelos computacionales que se componen de múltiples capas de procesamiento aprendan representaciones de datos con múltiples niveles de abstracción. En el Procesamiento de Lenguaje Natural, la idea principal es representar las unidades de texto (morfemas, palabras, frases, documentos, etc.) como vectores de características.
Cada entrada del vector representa una característica oculta dentro del significado de la unidad de texto. Estas representaciones pueden revelar dependencias semánticas o sintácticas. Nuestro trabajo aquí consiste en investigar modelos de representación multimodal que permitan facilitar la clasificación o la interpretación humana de las propiedades inherentes al uso del lenguaje, desde el punto de vista de la lingüística o de la cognición.
Minería de Texto
La minería de textos es el proceso de obtención de información de alta calidad por una computadora a partir de un texto. Implica el descubrimiento de información nueva, previamente desconocida, mediante la extracción automática de información.
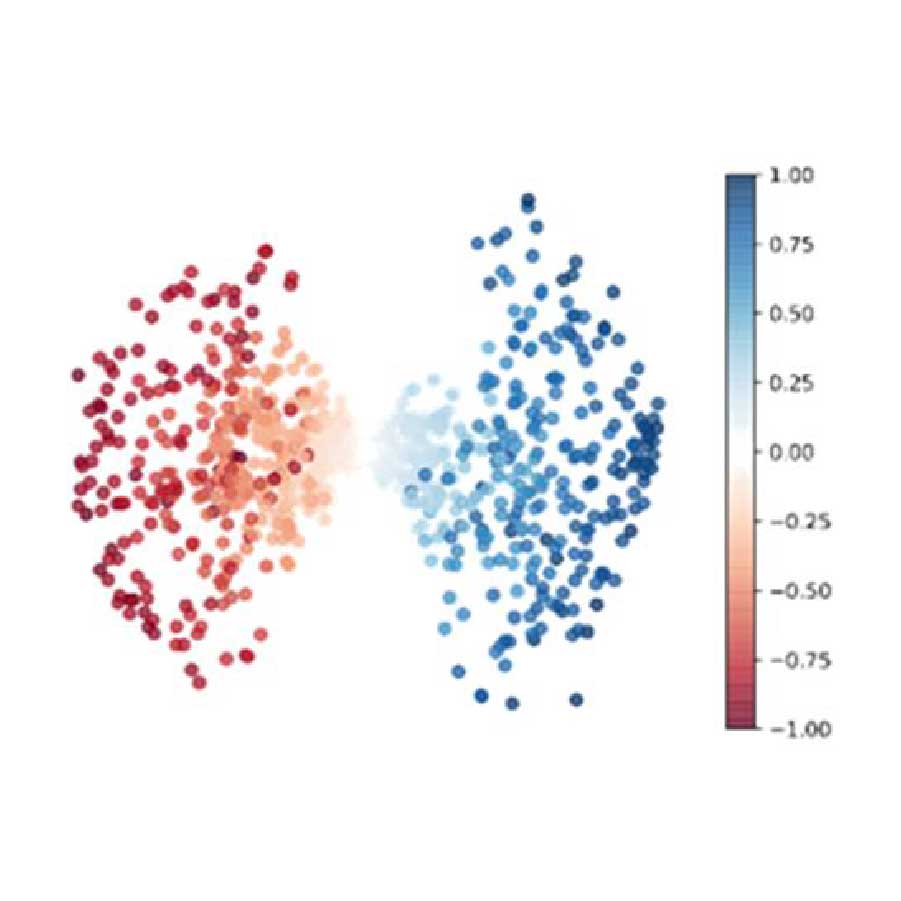
La minería de textos es un proceso automático que utiliza el PLN para extraer información valiosa del texto no estructurado. Al transformar los datos en información que las máquinas pueden entender, la minería de textos automatiza el proceso de clasificación de los textos por sentimiento, tema e intención.
Nuestro trabajo aquí consiste en investigar modelos matemáticos y computacionales para el análisis de sentimientos, la recuperación de información, el resumen automático de textos, o la clasificación multimodal.
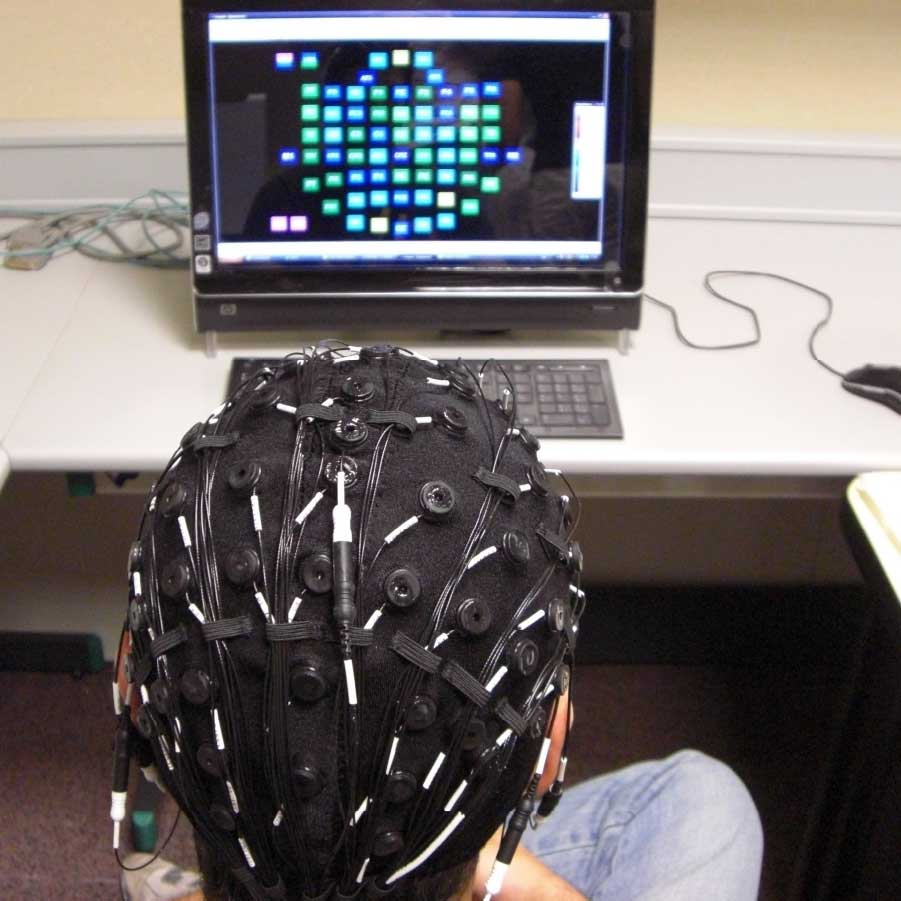
Interfaces cerebro-computadora
La interacción hombre-máquina es un campo de investigación en expansión. En nuestro enfoque deseamos desarrollar Interfaces Cerebro Computador (BCI por sus siglas en inglés) para el control de dispositivos electromecánicos que pueden ser robots o sistemas prostéticos. Un aspecto de gran importancia de las BCI radica en que son herramientas que permiten establecer nuevos canales de interacción en personas discapacitadas compensando en algún grado capacidades ausentes o perdidas.
Nuestro objetivo es obtener modelos de interacción hombre-máquina, mediante el análisis de las señales de electroencefalografía (EEG) registradas durante la imaginación del movimiento voluntario de extremidades. Una característica común a casi todos los desarrollos en BCI es el aprovechamiento de la cognición motriz y la capacidad de controlar voluntariamente los ritmos sensoriomotrices vinculados a ella. Más aún, en estudios reportados en la literatura, se ha observado que los sujetos son capaces de controlar voluntariamente determinados rasgos de las señales de EEG. Esto permite obtener variables de control que vinculan estas señales con la actividad mental del sujeto, como es el caso de las imaginaciones motoras.
Actualmente estamos estudiando un método que permite encontrar indicios del régimen de sincronización de fase en un espectro de frecuencias amplio entre diferentes áreas de la corteza cerebral, incluyendo interacciones interhemisféricas, a pesar de la variabilidad intrínseca de las señales.
proyectos
Actualmente contamos con fondos de CONACYT para el desarrollo de un proyecto de Ciencia Básica en torno al modelado de relaciones discursivas